
重生之我学操作系统——第29章 基于锁的并发数据结构
一、并发计数器
一个简单的计数器
typedef struct counter_t{
int value;
} counter_t;
void init(counter_t* c){
c->value = 0;
}
void increment(counter_t* c){
c->value++;
}
void decrement(counter_t* c){
c->value--;
}
int get(counter_t* c){
int rc = c->value;
return rc;
}
哪些地方需要加锁?
一种加锁方法:(全局都加上锁)
typedef struct counter_t{
int value;
pthread_mutex_t lock;
} counter_t;
void init(counter_t* c){
c->value = 0;
pthread_mutex_init(&c->lock, NULL);
}
void increment(counter_t* c){
pthread_mutex_lock(&c->lock);
c->value++;
pthread_mutex_unlock(&c->lock);
}
void decrement(counter_t* c){
pthread_mutex_lock(&c->lock);
c->value--;
pthread_mutex_unlock(&c->lock);
}
int get(counter_t* c){
pthread_mutex_lock(&c->lock);
int rc = c->value;
pthread_mutex_unlock(&c->lock);
return rc;
}
问题:扩展性差
当线程数量变多,性能下降明显
违背了并发的初衷!
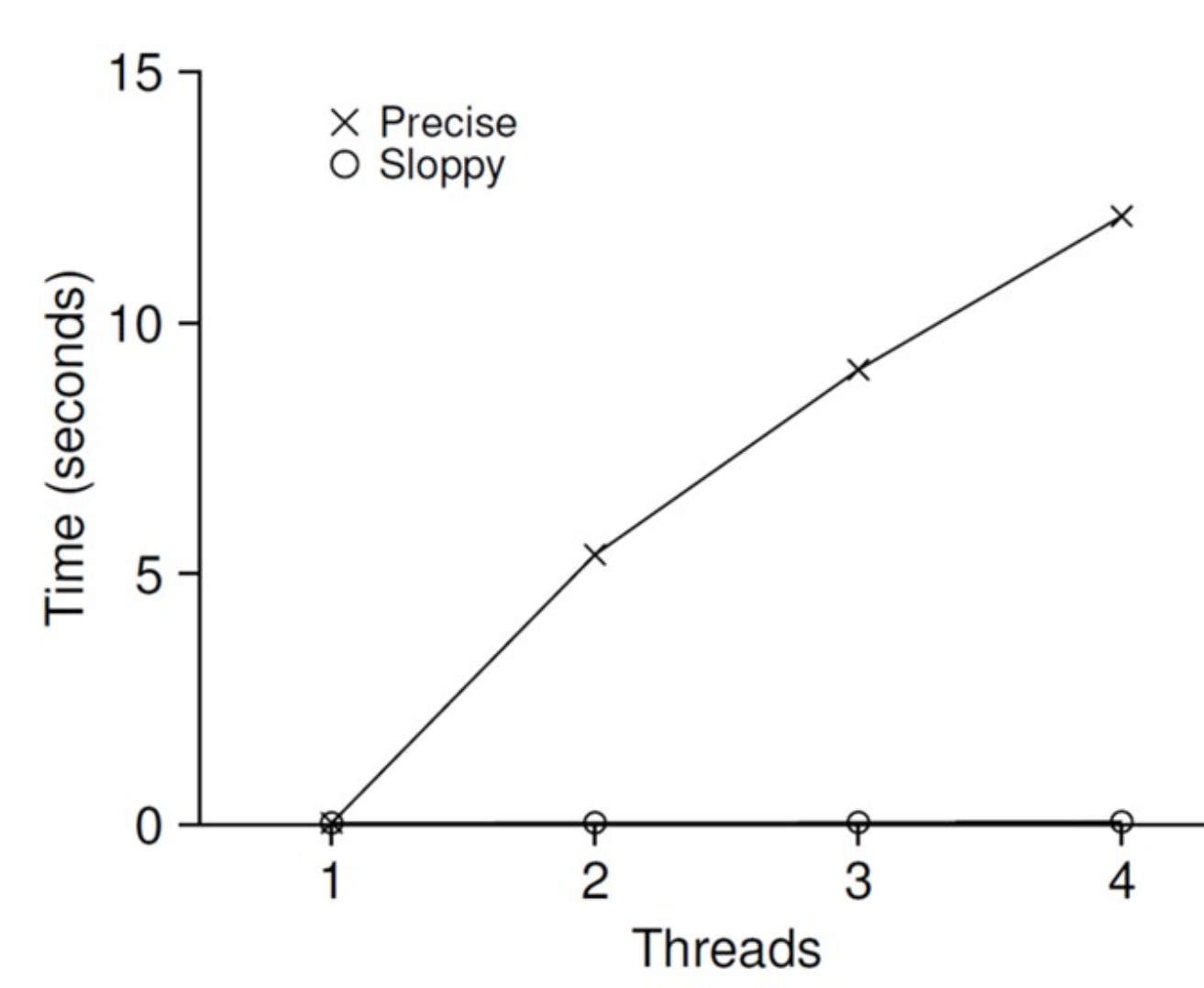
可扩展的计数:懒惰计数器(sloppy counter)
一个全局计数器和多个局部计数器(每个CPU核一个)
如何实现计数?如何加锁?
一个全局计数器和多个局部计数器(每个CPU核一个)
一个全局锁(用来保护全局计数器)
每个局部计数器一个锁(用来保护局部计数器)
局部计数器的值会定期转移到全局计数器
取决于阈值S(sloppiness)
typedef struct __counter_t {
int global; // global count
pthread_mutex_t glock; // global lock
int local[NUMCPUS]; // local count (per CPU)
pthread_mutex_t lock[NUMCPUS]; // ... and locks
int threshold; // update frequency
} counter_t;
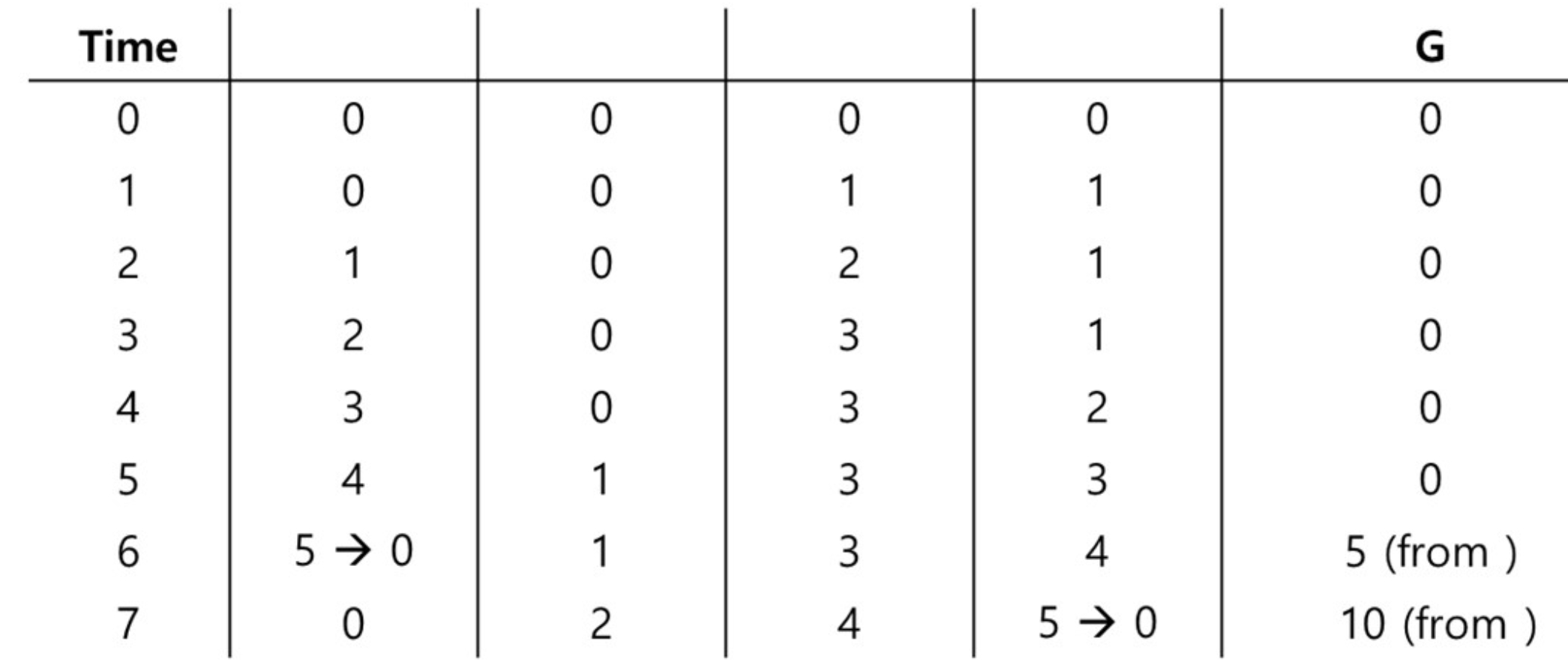
- 阈值S调节了计数器的准确性和性能
- S越大,可扩展性越强
- S越小,全局计数器越精确
权衡是0S设计中经典的主题。
二、并发链表
typedef struct node_t{
int key;
struct node_t* next;
} node_t;
typedef struct list_t{
node_t* head;
pthread_mutex_t lock;
} list_t;
void ListInit(list_t* L){
L->head = NULL;
pthread_mutex_init(&L->lock, NULL);
}
int List_Insert(list_t* L, int key){
pthread_mutex_lock(&L->lock);
node_t* new = malloc(sizeof(node_t));
if(new == NULL){
perror("malloc");
pthread_mutex_unlock(&L->lock);
return -1; /* fail */
}
new->key = key;
new->next = L->head;
L->head = new;
pthread_mutex_unlock(&L->lock);
return 0; /* success */
}
int List_Lookup(list_t *L, int key) {
pthread_mutex_lock(&L->lock);
node_t *curr = L->head;
while (curr) {
if (curr->key == key) {
pthread_mutex_unlock(&L->lock);
return 0; // success
}
curr = curr->next;
}
pthread_mutex_unlock(&L->lock);
return -1; // failure
}
并发链表:改进
void List_Insert(list_t* L, int key){
node_t* new = malloc(sizeof(node_t));
if(new == NULL){
perror("malloc");
return;
}
new->key = key;
// just lock critical section
pthread_mutex_lock(&L->lock);
new->next = L->head;
L->head = new;
pthread_mutex_unlock(&L->lock);
}
三、并发队列
- Michael and Scott 并发队列
- 队列的头部有一把锁(保护出队列操作)
- 队列的尾部有一把锁(保护入队列操作)
- 添加了一个假节点
- 在队列初始化代码里分配,该节点分开了头和尾操作
队列在多线程程序中被广泛使用
typedef struct __node_t {
int value;
struct __node_t *next;
} node_t;
typedef struct __queue_t {
node_t *head;
node_t *tail;
pthread_mutex_t headLock;
pthread_mutex_t tailLock;
} queue_t;
void Queue_Init(queue_t *q) {
node_t *tmp = malloc(sizeof(node_t));
tmp->next = NULL;
q->head = q->tail = tmp;
pthread_mutex_init(&q->headLock, NULL);
pthread_mutex_init(&q->tailLock, NULL);
}
void Queue_Enqueue(queue_t *q, int value) {
node_t *tmp = malloc(sizeof(node_t));
assert(tmp != NULL);
tmp->value = value;
tmp->next = NULL;
pthread_mutex_lock(&q->tailLock);
q->tail->next = tmp; // 新节点放在尾部
q->tail = tmp;
pthread_mutex_unlock(&q->tailLock);
}
int Queue_Dequeue(queue_t *q, int *value) {
pthread_mutex_lock(&q->headLock);
node_t *tmp = q->head;
node_t *newHead = tmp->next;
if (newHead == NULL) {
pthread_mutex_unlock(&q->headLock);
return -1; // queue was empty
}
*value = newHead->value;
// 取走的是head指向 的第2个节点内容
q->head = newHead;
pthread_mutex_unlock(&q->headLock);
free(tmp);
return 0;
}
四、并发散列表(Hash Table)
#define BUCKETS (101)
typedef struct __hash_t {
list_t lists[BUCKETS];
} hash_t;
void Hash_Init(hash_t *H) {
int i;
for (i = 0; i < BUCKETS; i++) {
List_Init(&H->lists[i]);
}
}
int Hash_Insert(hash_t *H, int key) {
int bucket = key % BUCKETS;
return List_Insert(&H->lists[bucket], key);
}
int Hash_Lookup(hash_t *H, int key) {
int bucket = key % BUCKETS;
return List_Lookup(&H->lists[bucket], key);
}
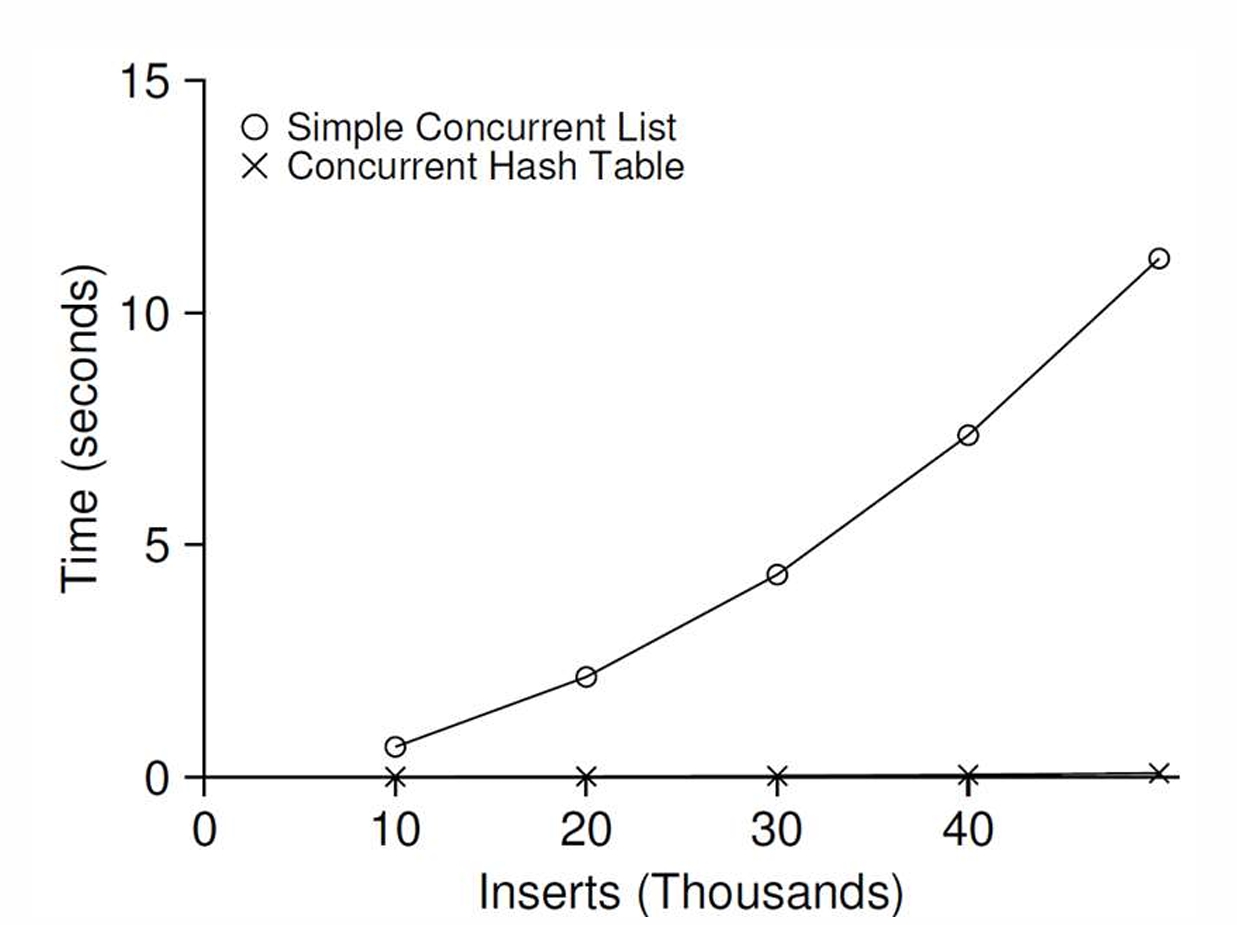
每个线程分别执行10000-50000次并发更新
简单的并发散列表,扩展性极好。
幻想安全区 ~ Dreamscape Haven by Satori5ama is licensed under
萌ICP备20239514号 | Powered by Hugo and Yinyang theme