
重生之我学操作系统——第26、27章 并发、线程API
问题:进程并发
// ... existing code ...
int sum1 = 0, sum2 = 0;
void p1() {
int i, tmp = 0;
for (i = 1; i <= 100; i++)
tmp += i;
sum1 += tmp;
}
void p2() {
int i, tmp = 0;
for (i = 101; i <= 200; i++)
tmp += i;
sum2 += tmp;
}
void p3() {
printf("sum: %d\n", sum1 + sum2);
}
int main() {
pid_t pid;
int stat;
pid = fork();
if (pid == 0) {
p1();
exit(0);
}
p2();
pid = wait(&stat);
p3();
return 0;
}
- 预期结果:20100
- 实际结果:10500
- 问题原因:
- 在
main()函数中,fork()创建了一个子进程。子进程执行p1(),而父进程执行p2()。 - 子进程中的
sum1的值不会被父进程所看到,因为每个进程都有自己的内存空间。 - 因此,父进程中的
sum1仍然是 0,而sum2是 15050(从 101 到 200 的和)。
- 在
一. 并发基本概念
1. 并发的概念
- 并发意味着多个计算任务在同一时间段发生
- 指在同一时间段内,多个任务在操作系统中交替执行。实际上,这些任务并不是真正同时执行,而是通过OS调度,快速地在多个任务之间切换,从而给用户一种多个任务同时进行的假象。
- 任务存在可并发成分
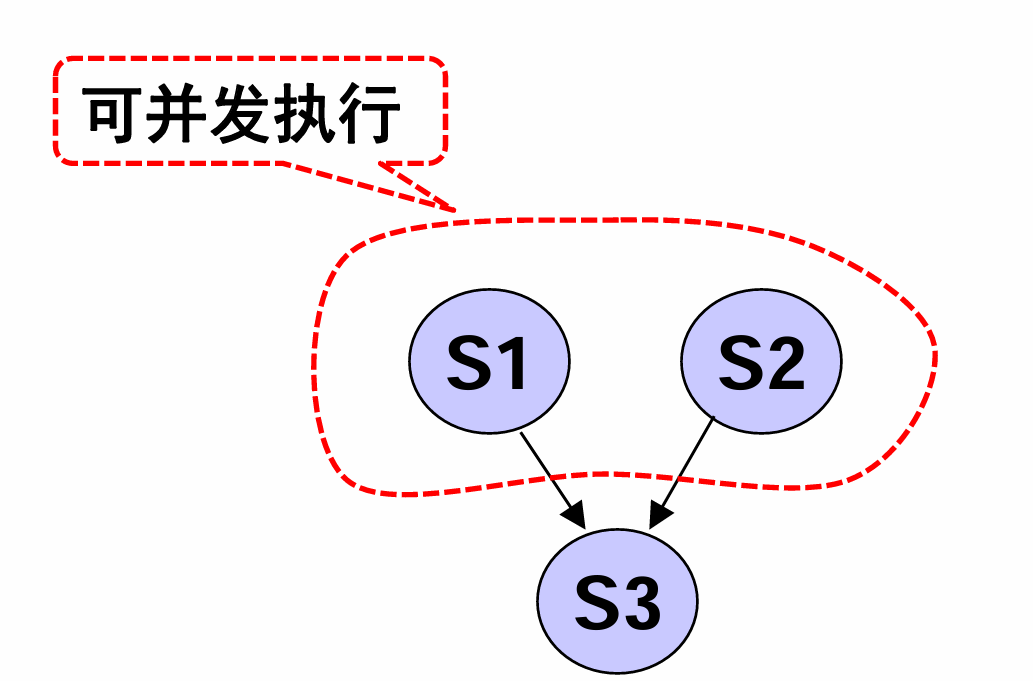
Parbegin
S1;
S2;
Parend
S3;
Dijkstra提出并行语句: Parbegin S1;S2; … Sn; Parend;
- 多进程实现并发
Parbegin
S1;
S2;
Parend
S3;
pid = fork();
if (pid == 0) {
S1; // 子进程执行的代码
exit(0);
}
S2; // 父进程执行的代码
wait(&status); // 等待子进程结束
S3; // 子进程结束后执行的代码
多进程实现并发有什么缺陷?
进程间通信(IPC)通常比线程间通信更复杂。进程之间不能直接共享内存,需要使用管道、消息队列、共享内存等机制进行数据交换
2. 线程
- 问题:不同进程有独立的内存地址空间,通信/共享复杂
- 创建一种新的并发机制:线程(thread)
- 进程的最小执行单元(也是OS调度的基本单元)
- 同一进程的不同线程共享同一个地址空间
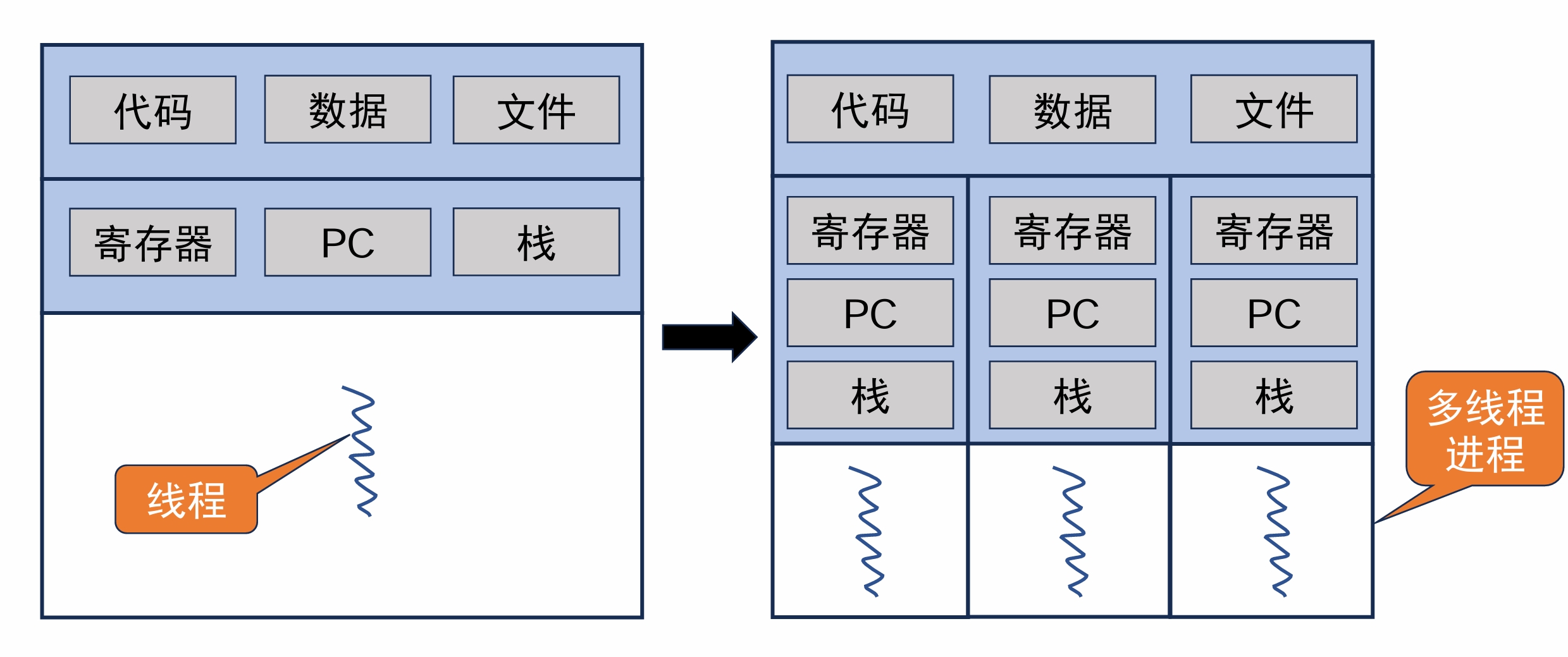
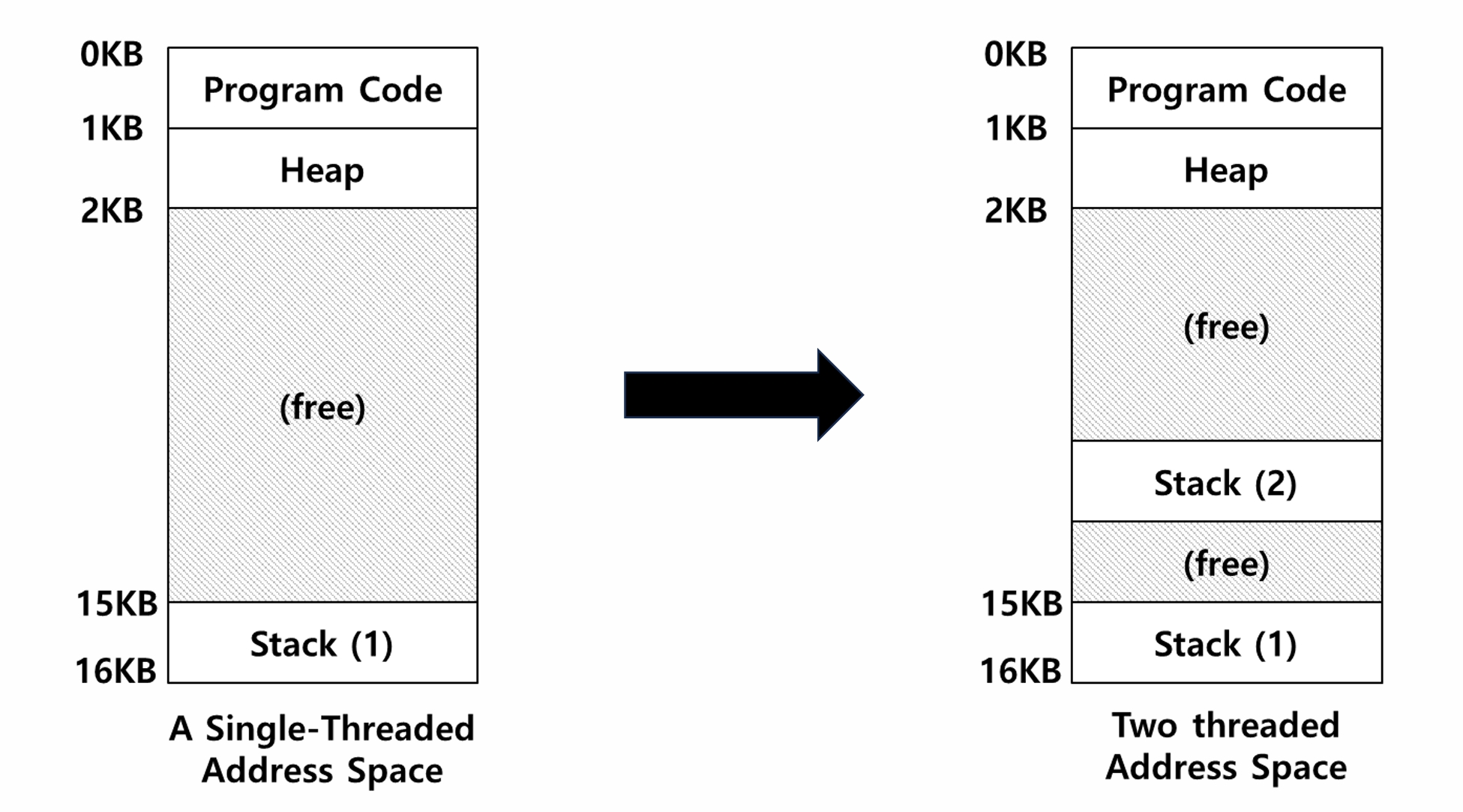
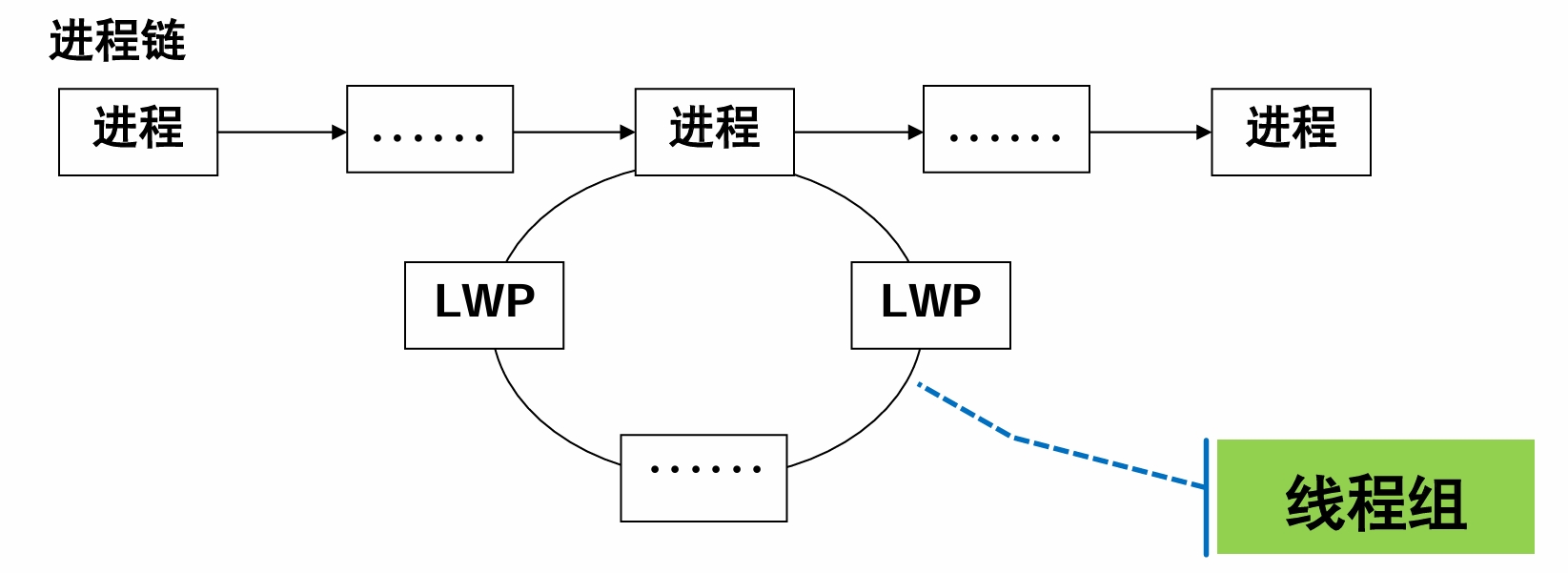
- Linux在进程中实现了线程——轻量级进程(Light-Weight Process, LWP)
- LWP和进程一起参与调度,在LWP基础上实现了线程库pthread
- 多线程实现并发
pthread_create(&t1, NULL, S1, NULL); // 创建线程 t1 执行 S1
S2(); // 主线程执行 S2
pthread_join(t1, &res); // 主线程等待线程 t1 结束 (同步关系)
S3; // 线程 t1 结束后执行 S3
- 多线程案例
int sum1 = 0, sum2 = 0;
// 全局变量被共享
void *p1() {
int i, tmp = 0;
for (i = 1; i <= 100; i++)
tmp += i;
sum1 += tmp;
}
void p2() {
int i, tmp = 0;
for (i = 101; i <= 200; i++)
tmp += i;
sum2 += tmp;
}
void p3() {
printf("sum: %d\n", sum1 + sum2);
}
int main() {
int res;
pthread_t t1;
void *thread_result;
res = pthread_create(&t1, NULL, p1, NULL);
// 线程创建后, 与主线程并发运行
if (res != 0) {
perror("failed to create thread");
exit(1);
}
p2();
res = pthread_join(t1, &thread_result);
if (res != 0) {
perror("failed to join thread");
exit(2);
}
p3();
return 0;
}
3. 临界区
案例:
int max;
volatile int counter = 0; // shared global variable
void *mythread(void *arg) {
char *letter = arg;
int i; // stack (private per thread)
printf("%s: begin [addr of i: %p]\n", letter, &i);
for (i = 0; i < max; i++) {
counter = counter + 1; // shared: only one
/* 对应asm代码:
mov 0x8049a1c, %eax
add $0x1, %eax
mov %eax, 0x8049a1c
*/
}
printf("%s: done\n", letter);
return NULL;
}
int main(int argc, char *argv[]) {
...
max = atoi(argv[1]);
pthread_t p1, p2;
printf("main: begin [counter = %d] [%p]\n", counter, &counter);
pthread_create(&p1, NULL, mythread, "A");
pthread_create(&p2, NULL, mythread, "B");
// join waits for the threads to finish
pthread_join(p1, NULL);
pthread_join(p2, NULL);
printf("main: done\n [counter: %d] [should: %d]\n", counter, max * 2);
return 0;
}
以相同输入重复运行上述代码,运行结果:
当输入的值超过一定范围后,重复运行结果常不稳定,且常不能得到正确结果(< 2*max)

- 临界区(Critical Section)
- 指访问共享变量的程序段,也称临界段
- 例如,上述案例中的
counter = counter + 1;
- 例如,上述案例中的
- 共享变量也成为临界资源
- 访问相同临界区的代码应该互斥执行(mutual exclusive)
- 竞争条件(race condition):指多个线程同时进入临界区,也称数据 竞争
- 我们希望保证临界区代码执行的原子性(atomicity)
- 指访问共享变量的程序段,也称临界段
- 利用锁(lock)来保证临界区的原子性
二、线程API
1. 线程创建
int pthread_create(
pthread_t *thread,
const pthread_attr_t *attr,
void *(*start_routine)(void *),
void *arg
//如参数或返回值类型不同于此,可以进行强制类型转换,可以没有参数
);
- thread: 线程结构体对象指针,代表线程
- attr: 属性,如栈大小、调度优先级等
- start_routine: 线程运行的主函数
- arg: 主函数要用到的参数
typedef struct __myarg_t {
int a;
int b;
} myarg_t;
void *mythread(void *arg) {
myarg_t *m = (myarg_t *)arg;
printf("%d %d\n", m->a, m->b);
return NULL;
}
typedef struct __myarg_t {
int a;
int b;
} myarg_t;
void *mythread(void *arg) {
myarg_t *m = (myarg_t *)arg;
printf("%d %d\n", m->a, m->b);
return NULL;
}
int main(...) {
pthread_t p;
int rc;
myarg_t args;
args.a = 10;
args.b = 20;
rc = pthread_create(&p, NULL, mythread, &args);
...
}
2. 等待线程结束
int pthread_join( pthread_t thread, void ** value_ptr );
- thread: 线程结构体对象指针,代表线程
- value_ptr: A pointer to the return value
- 返回值的类型是void *,可通过类型转换变成其它类
typedef struct __myarg_t {
int a;
int b;
} myarg_t;
typedef struct __myret_t {
int x;
int y;
} myret_t;
void *mythread(void *arg) {
myarg_t *m = (myarg_t *)arg;
printf("%d %d\n", m->a, m->b);
myret_t *r = malloc(sizeof(myret_t));
r->x = 1;
r->y = 2;
return (void *)r;
}
int main(int argc, char *argv[]) {
int rc;
pthread_t p;
myret_t *m;
myarg_t args;
args.a = 10;
args.b = 20;
pthread_create(&p, NULL, mythread, &args);
pthread_join(p, (void **)&m);
printf("returned %d %d\n", m->x, m->y);
free(m); // 释放分配的内存
return 0;
}
简单值传递不必打包
void *mythread(void *arg) {
int m = (int)arg;
printf("%d\n", m);
return (void *)(m + 1);
}
int main(int argc, char *argv[]) {
pthread_t p;
int rc, m;
pthread_create(&p, NULL, mythread, (void *)100);
pthread_join(p, (void **)&m);
printf("returned %d\n", m);
return 0;
}
例子:危险代码
void *mythread(void *arg) {
myarg_t *m = (myarg_t *)arg;
printf("%d %d\n", m->a, m->b);
myret_t r; // ALLOCATED ON STACK: BAD!
// 应使用malloc进行内存的分配
r.x = 1;
r.y = 2;
return (void *)&r;
}
函数的局部变量在函数返回时被释放,之后不能再用
3. 锁(lock)
- 可为临界区提供互斥访问
pthread_mutex_t lock;
int rc = pthread_mutex_init(&lock, NULL);
assert(rc == 0); // always check success!
pthread_mutex_lock(&lock);// 若锁被占用,则等待
x = x + 1; // your critical section
pthread_mutex_unlock(&lock);// 只有已获得锁的线程才能解锁
- 锁相关其他API
int pthread_mutex_trylock(pthread_mutex_t *mutex);
// 若已被锁住,则立刻返回
int pthread_mutex_timelock(
pthread_mutex_t *mutex,
struct timespec *abs_timeout
);
//若超时,则放弃、返回
幻想安全区 ~ Dreamscape Haven by Satori5ama is licensed under
萌ICP备20239514号 | Powered by Hugo and Yinyang theme